What is TLB and why you should care

TLB stands for translation lookaside buffer. It stores translations from virtual memory to physical memory addresses and is one element of MMU (memory management unit) of a CPU. This one component which is often overlooked can have significant impact on your program. As you could have seen in my previous post that using hugepages can make a big difference in terms of a program runtime. Majority of the improvement in that example was due to reduction in TLB lookups and misses. Here we will talk more about TLB and look at the impact of page walking that happens in case of TLB misses.
Virtual to physical address translation
Virtual address (VA) is translated into a physical one via a series of lookup tables. In x86 lingo these are called PML4 (Page map level4 table), PDP (Page directory pointer), PD (Page directory), PT (Page table). The tables are looked up PML4 → PDP → PD → PT. In order to translate a virtual into a physical address first address is looked up in the tables mentioned. However, that address is a pointer to page frame. A page frame contains a set of addresses. An entry in PT points to an address which is start of a 4kb range.
We can configure page tables such that PD is a pointer to page frame (instead of it being a pointer to a page table). This page frames are larger (e.g. 2Mb in size) and require less work to translate a VA into a PA.
An astute reader might have noticed that vast majority of times an address is not “translated” at all and instead it is looked up in TLB. What is really looked up in the TLB is page frame address.
Why do hugepages perform so well?
To better understand why hugepages perform so well and under which conditions let’s first make sure we have some information about TLB on machine that will be used for testing:
cache and TLB information (2):
0x63: data TLB: 2M/4M pages, 4-way, 32 entries
data TLB: 1G pages, 4-way, 4 entries
0x03: data TLB: 4K pages, 4-way, 64 entries
0xc3: L2 TLB: 4K/2M pages, 6-way, 1536 entriesData TLB for 4K pages (regular pages) consists of 64 entries and is “4-way” associative. TLB for 2M pages (hugepages) has 32 entries and is also “4-way” associative.
When using 4K pages TLB can store translations for up to 256Kb ( =64 entries * 4K ) of memory. That means that if we wanted to store a vector of 8 byte integers (uint32_t for example) the TLB can “accomodate” up to 32000 (=256Kb / 8) elements. If the vector is larger than that we will start experiencing slowdowns because entries will be moved in and out of TLB during runtime. Placing an entry in TLB requires walking the page table which adds extra latency.
If we use 2MB hugepages, TLB can accomodate for up to 64MB ( = 32 * 2MB) or up to 8 million 8 byte integers. If we use 1GB pages it goes all the way up to 4GB!
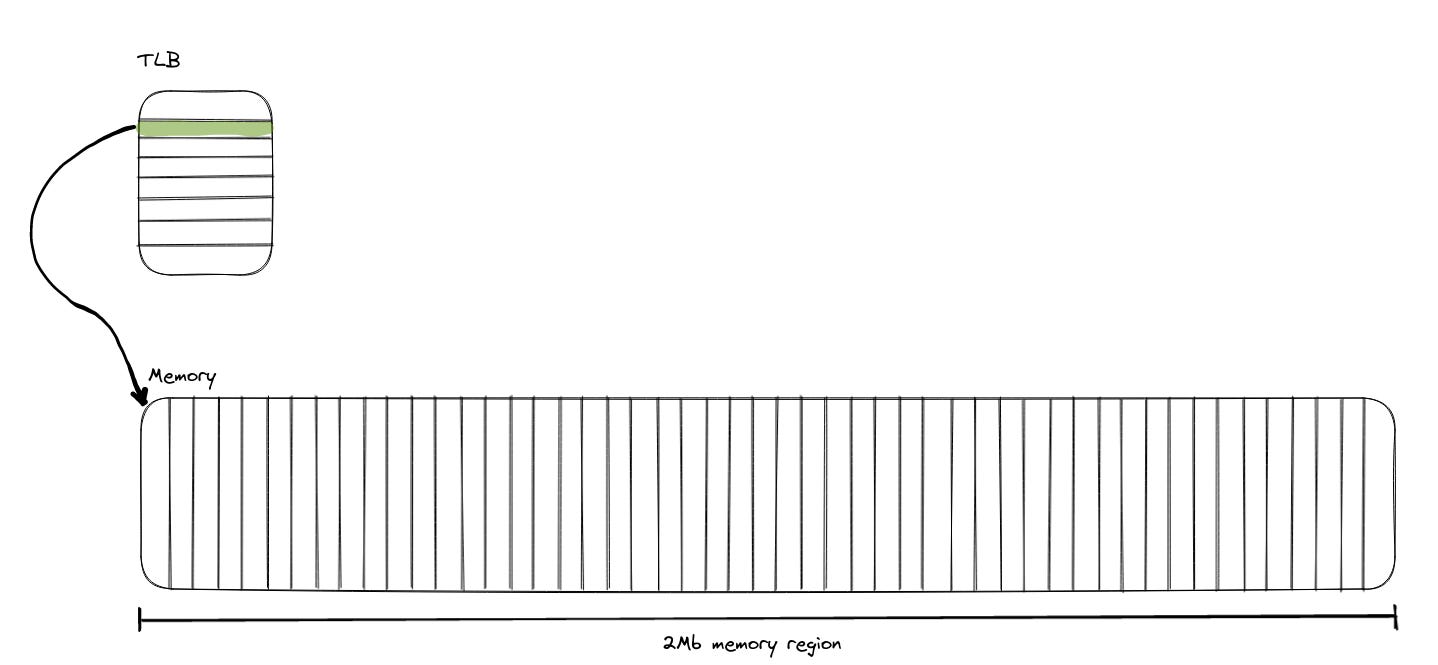
To accomodate 64MB we would need 16000 regular (4KB) pages. That’s more than what can fit into TLB L2 cache (TLB in most modern processors is also “multi-level”, like regular data and instruction cache).
Ok, but how much of a difference are we talking about here? To get a better understanding I will run this program twice. Once I will use default memory allocator and the other run will use memory allocator that uses 2M hugepages.

The above graph shows number of page walks for two runs. Green line represents case where default memory allocator is used which internally uses regular 4KB pages. Blue line represents a run where a custom memory allocator which uses 2MB pages (aka hugepages) was used. You can see that number of page walks is significantly lower and that the program completed about 3x faster.
Conclusion
The above results demonstrate why it is still important to think about how programs work and not treat CPU like a black box. Better understanding CPU will allow your team to provide outstanding services. These kind of optimisations will, in my opinion, be more and more important in the future as race to train larger and larger AI models continue. These kind of optimizations can translate to significantly faster training and/or lower electricity usage (which can be measured in millions of $$$, especially when working with AI).
If you have some questions around hugepages, TLB or CPUs in general feel free to reach out via the chat, leave a comment or message me via Twitter @mvuksano.
